
Migrating Java Applications to HP-UX









33
PS: ioctl 3769 29485 769.1 217.9 4.82 225.66
PS: poll 3759 29225 767.1 216.0 8.01 131.72
PS: send 49537 379390 10109.5 2804.0 0.80 26.20
PS: sched_yield 443 3997 90.4 29.5 0.09 1.67
PS: ksleep 3990 31546 814.2 233.1 56.42 3283.72
PS: kwakeup 3980 31307 812.2 231.3 0.01 0.13
...
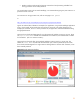
Focusing just on sched_yield rates (grep sched_yield), the following screen is a snippet from
single instance Java. Note the sched_yield rates (3rd column) get as high 90K per second.
Figure 29 sched_yield rates (before)
...
PS: sched_yield 704456 704456 71157.1 35222.8 0.59 0.59
PS: sched_yield 447103 1151559 45161.9 38385.3 0.40 1.00
PS: sched_yield 854681 2006240 85468.1 50156.0 1.41 2.41
PS: sched_yield 3228 2009468 322.8 40109.1 0.01 2.42
PS: sched_yield 427631 2437099 43195.0 40618.3 0.37 2.79
PS: sched_yield 80744 2517843 8074.4 35969.1 0.10 2.90
PS: sched_yield 125310 2643153 12786.7 33080.7 0.12 3.01
PS: sched_yield 10114 2653267 1011.4 29480.7 0.02 3.04
PS: sched_yield 86729 2739996 8672.9 27372.5 0.09 3.13
PS: sched_yield 20274 2760270 2047.8 25093.3 0.05 3.18
PS: sched_yield 6122 2766392 651.2 23149.7 0.03 3.21
PS: sched_yield 4212 2770604 405.0 21312.3 0.02 3.23
PS: sched_yield 480955 3251559 48581.3 23225.4 0.43 3.65
PS: sched_yield 459844 3711403 46448.8 24759.1 0.51 4.17
PS: sched_yield 368195 4079598 36454.9 25497.4 0.34 4.50
PS: sched_yield 9701 4089299 979.8 24054.7 0.05 4.55
PS: sched_yield 107817 4197116 10890.6 23317.3 0.10 4.65
PS: sched_yield 322367 4519483 32236.7 23786.7 0.31 4.96
PS: sched_yield 918902 5438385 92818.3 27205.5 0.78 5.73
PS: sched_yield 3603 5441988 360.3 25914.2 0.02 5.76
...
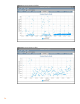
The following screen is a snippet after switching to multi-instance/psets.
Figure 30 sched_yield rates (after)
...
PS: sched_yield 716 2887 146.1 24.0 0.08 1.45
PS: sched_yield 475 3362 95.0 26.8 0.10 1.56
PS: sched_yield 443 3997 90.4 29.5 0.09 1.67
PS: sched_yield 4217 8214 843.4 58.5 0.11 1.78
PS: sched_yield 6101 14315 1245.1 98.5 0.06 1.85
PS: sched_yield 17678 31993 3535.6 212.8 0.02 1.87
PS: sched_yield 1230 33223 246.0 213.9 0.05 1.91
PS: sched_yield 8189 41412 1671.2 258.5 0.08 1.99
PS: sched_yield 9697 51148 1939.4 300.3 0.08 2.08
PS: sched_yield 26599 77747 5319.8 443.5 0.03 2.11
PS: sched_yield 3372 81119 688.1 450.1 0.00 2.11
PS: sched_yield 335 81575 68.3 428.8 0.06 2.18
PS: sched_yield 9028 90603 1805.6 464.1 0.13 2.31
PS: sched_yield 1821 92424 371.6 461.6 0.01 2.32
PS: sched_yield 1037 93461 207.4 455.2 0.01 2.33
PS: sched_yield 1571 95032 314.2 451.8 0.04 2.37
PS: sched_yield 16607 111639 3389.1 518.7 0.01 2.38
PS: sched_yield 734 112373 149.7 510.3 0.00 2.39
PS: sched_yield 5939 118312 1187.8 525.3 0.08 2.47
PS: sched_yield 3713 122025 757.7 530.0 0.00 2.47
...
As you can see, sched_yield rates are substantially reduced after switching to multiple Java
instances running in psets, indicating reduced lock contention.
Finally, figures 31 and 32 compare scavenge durations before and after optimization. Even though
scavenge GCs are quick and were not causing a major problem, note the first screenshot shows
occasional higher scavenge times, as high as 500ms. In the second screenshot, the scavenges are
more uniformly under 150ms, with only a few hitting 250ms.