
Open Source Object Storage for Unstructured Data: Ceph on HP ProLiant SL4540 Gen8 Servers










Table Of Contents
- Executive summary
- Introduction
- Overview
- Solution components
- Workload testing
- Configuration guidance
- Bill of materials
- Summary
- Appendix A: Sample Reference Ceph Configuration File
- Appendix B: Sample Reference Pool Configuration
- Appendix C: Syntactical Conventions for command samples
- Appendix D: Server Preparation
- Appendix E: Cluster Installation
- Naming Conventions
- Ceph Deploy Setup
- Ceph Node Setup
- Create a Cluster
- Add Object Gateways
- Apache/FastCGI W/100-Continue
- Configure Apache/FastCGI
- Enable SSL
- Install Ceph Object Gateway
- Add gateway configuration to Ceph
- Redeploy Ceph Configuration
- Create Data Directory
- Create Gateway Configuration
- Enable the Configuration
- Add Ceph Object Gateway Script
- Generate Keyring and Key for the Gateway
- Restart Services and Start the Gateway
- Create a Gateway User
- Appendix F: Newer Ceph Features
- Appendix G: Helpful Commands
- Appendix H: Workload Tool Detail
- Glossary
- For more information
Reference Architecture | Product, solution, or service
“knew” which Ceph OSD Daemon had which object, it would create a tight coupling between the Ceph Client and the Ceph
OSD Daemon. Instead, the CRUSH algorithm maps each object to a placement group and then maps each placement group
to one or more Ceph OSD Daemons. This layer of indirection allows Ceph to rebalance dynamically when new Ceph OSD
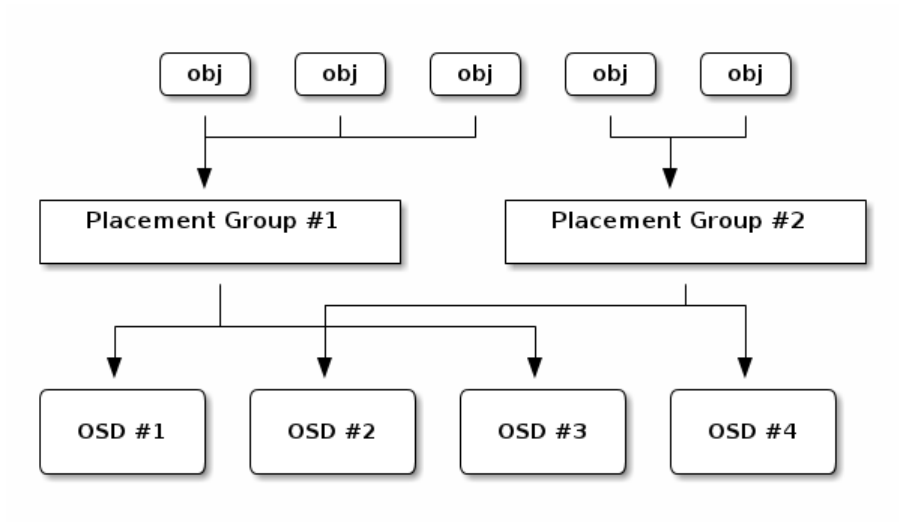
Daemons and the underlying OSD devices come online. The following diagram depicts how CRUSH maps objects to
placement groups, and placement groups to OSDs.
Figure 3: Mapping Objects to OSDs
The leverage of existing storage technology takes place under the OSD Daemon. When the RADOS object data is written, it’s
currently written as a file within a directory on the OSD. There’s more to it than that—the metadata must also be
committed separately, and Ceph reserves some storage for journaling—but the distribution across the file system is
essentially how object data and placement groups are implemented.
Scaling/Consistency/Failure Handling
With an understanding of the roles of the cluster and how data is stored, it’s also important to understand how the integrity
of data is protected and maintained.
Replication
– in addition to the benefit of data locality, replication provides the failure tolerance required by large scale. Like
Ceph Clients, Ceph OSD Daemons use the CRUSH algorithm but the Ceph OSD Daemon uses it to compute where replicas of
objects should be stored (and for rebalancing). For the recommended configuration, there are 3 copies of any object data
written—one on the Primary OSD for the placement group and two replicas. This replication level is user configurable; the
default without modifying ceph.conf is 2 replicas.
In a typical write scenario, a client uses the CRUSH algorithm to compute where to store an object, maps the object to a pool
and placement group, then looks at the CRUSH map to identify the primary OSD for the placement group.
The client writes the object to the identified placement group in the primary OSD. Then, the primary OSD with its own copy
of the CRUSH map identifies the secondary and tertiary OSDs for replication purposes, replicates the object to the
appropriate placement groups in the secondary and tertiary OSDs, and responds to the client once it has confirmed the
object and its replicas were stored successfully.
9