
Open Source Object Storage for Unstructured Data: Ceph on HP ProLiant SL4540 Gen8 Servers










Table Of Contents
- Executive summary
- Introduction
- Overview
- Solution components
- Workload testing
- Configuration guidance
- Bill of materials
- Summary
- Appendix A: Sample Reference Ceph Configuration File
- Appendix B: Sample Reference Pool Configuration
- Appendix C: Syntactical Conventions for command samples
- Appendix D: Server Preparation
- Appendix E: Cluster Installation
- Naming Conventions
- Ceph Deploy Setup
- Ceph Node Setup
- Create a Cluster
- Add Object Gateways
- Apache/FastCGI W/100-Continue
- Configure Apache/FastCGI
- Enable SSL
- Install Ceph Object Gateway
- Add gateway configuration to Ceph
- Redeploy Ceph Configuration
- Create Data Directory
- Create Gateway Configuration
- Enable the Configuration
- Add Ceph Object Gateway Script
- Generate Keyring and Key for the Gateway
- Restart Services and Start the Gateway
- Create a Gateway User
- Appendix F: Newer Ceph Features
- Appendix G: Helpful Commands
- Appendix H: Workload Tool Detail
- Glossary
- For more information
Reference Architecture| Ceph on HP ProLiant SL4540 Gen8 Servers
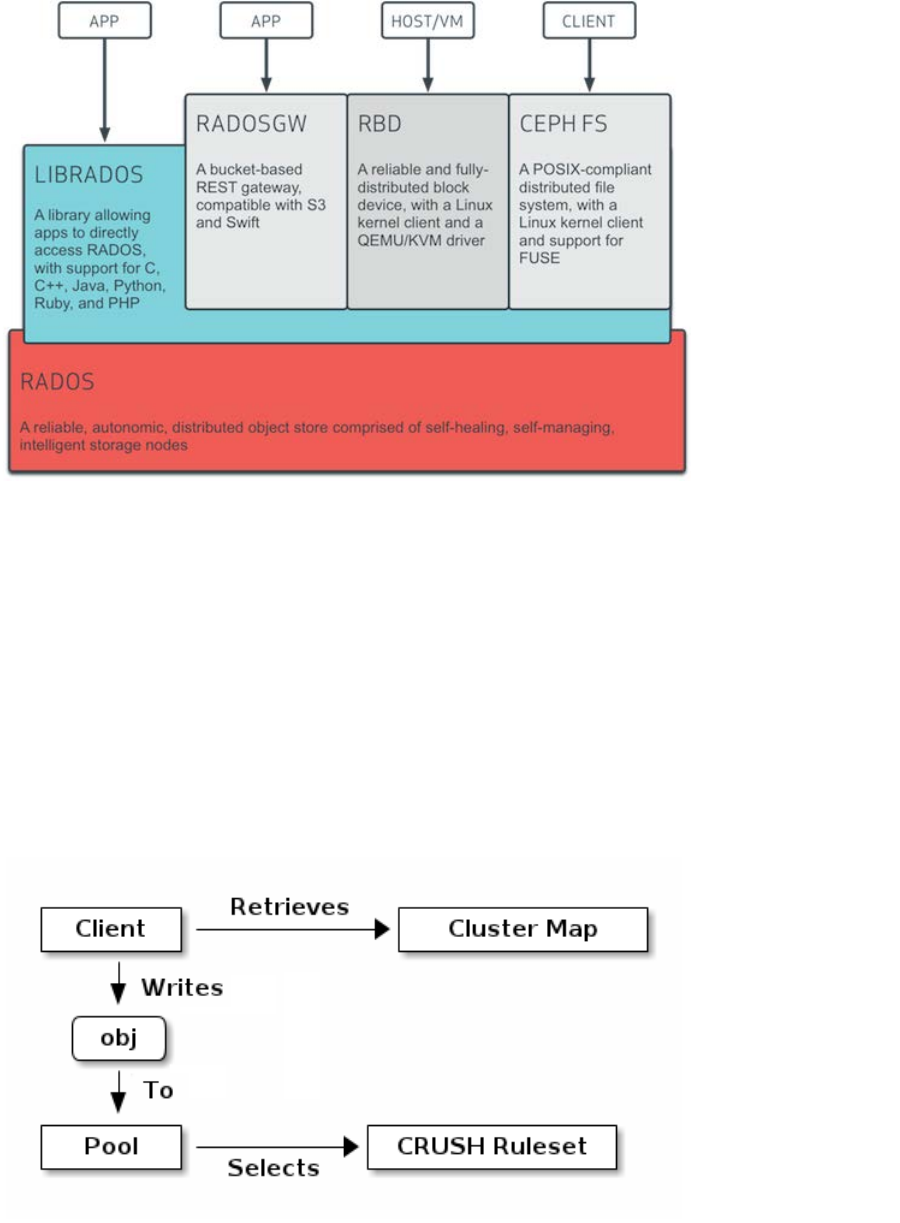
Figure 1: Cluster Access Methods
The core of mapping a HTTP GET/PUT or block read/write to Ceph objects from any of the access methods is CRUSH
(Controlled Replication Under Scalable Hashing). It is the algorithm Ceph uses to compute object storage locations. Per the
picture above, all access methods are converted into some number of Ceph native objects on the back end.
The Ceph storage system supports the notion of ‘Pools’, which are logical partitions for storing objects. Pools set the
following parameters:
• Ownership/access of objects
• The number of object replicas
• The number of placement groups
• The CRUSH Rule set to use
Ceph Clients retrieve a cluster map from a Ceph Monitor, and write objects to pools. The pool’s size, number of replicas, the
CRUSH rule set, and the number of placement groups determine how Ceph will place the data.
Figure 2: Client IO to a Pool
Each pool has a number of placement groups (PGs). CRUSH maps PGs to OSDs dynamically. When a Ceph Client stores
objects, CRUSH will map each object to a placement group.
Mapping objects to placement groups creates a layer of indirection between the Ceph OSD Daemon and the Ceph Client. The
Ceph Storage Cluster must be able to grow (or shrink) and rebalance where it stores objects dynamically. If the Ceph Client
8