
White Papers










Table Of Contents
- Executive Summary (updated May 2011)
- 1. Introduction
- 2. Dell NFS Storage Solution Technical Overview
- 3. NFS Storage Solution with High Availability
- 4. Evaluation
- 5. Performance Benchmark Results (updated May 2011)
- 6. Comparison of the NSS Solution Offerings
- 7. Conclusion
- 8. References
- Appendix A: NSS-HA Recipe (updated May 2011)
- A.1. Pre-install preparation
- A.2. Server side hardware set-up
- A.3. Initial software configuration on each PowerEdge R710
- A.4. Performance tuning on the server
- A.5. Storage hardware set-up
- A.6. Storage Configuration
- A.7. NSS HA Cluster setup
- A.8. Quick test of HA set-up
- A.9. Useful commands and references
- A.10. Performance tuning on clients (updated May 2011)
- A.11. Example scripts and configuration files
- Appendix B: Medium to Large Configuration Upgrade
- Appendix C: Benchmarks and Test Tools
Dell HPC NFS Storage Solution - High Availability Configurations
Page 18
4) Private switch failure
5) Fence device failure
6) One SAS link failure
7) Multiple SAS link failures
This section describes the NSS-HA response to failures. Details on how to configure the solution to
handle these failure scenarios are provided in Appendix A: NSS-HA .
Server response to a failure
Server response was recorded in how the HA cluster responds to a failure event. Time to recover
from a failure was used as a performance metric. Time was measured from the point when the
fault was injected in the server running the HA service (active) till the service was migrated and
running on the other server (passive).
1) Server failure - simulated by introducing a kernel panic.
When the active server fails, the heartbeat between the two servers is interrupted. The passive
server waits for a defined period of time and then attempts to fence the active server. The
default timeout period before a server is declared as dead is 10 seconds. This parameter is
tunable. Once fencing is successful, the passive server takes ownership of the cluster service.
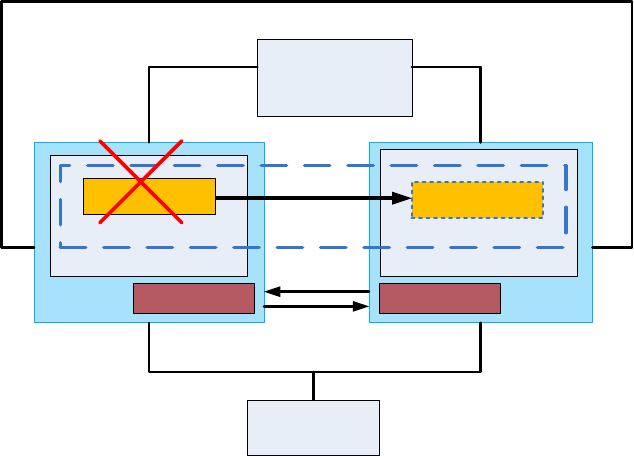
Figure 7 - Failover Procedure in Case of a Server Failure
Private Network
Clients
Active Server
Public Network
Passive Server
Failover
R710
Storage
Array
HA Service HA Service
RHEL 5.5 RHEL 5.5
RHCS
Fence deviceFence device
R710
Fencing
Figure 7 shows the failover procedure in this case. After the occurrence of a failure in the
active server, the RHCS agent running on the passive server detects the missing heartbeat.
(The process of detection may take a few seconds according to the set timeout value.) Once
the failure on the active server is detected, the passive server fences and reboots the active
server via a fence device before attempting to take ownership of the cluster service. This is to
ensure data integrity. At this point the HA service is migrated or failed over to the passive