
White Papers










Table Of Contents
- Executive Summary (updated May 2011)
- 1. Introduction
- 2. Dell NFS Storage Solution Technical Overview
- 3. NFS Storage Solution with High Availability
- 4. Evaluation
- 5. Performance Benchmark Results (updated May 2011)
- 6. Comparison of the NSS Solution Offerings
- 7. Conclusion
- 8. References
- Appendix A: NSS-HA Recipe (updated May 2011)
- A.1. Pre-install preparation
- A.2. Server side hardware set-up
- A.3. Initial software configuration on each PowerEdge R710
- A.4. Performance tuning on the server
- A.5. Storage hardware set-up
- A.6. Storage Configuration
- A.7. NSS HA Cluster setup
- A.8. Quick test of HA set-up
- A.9. Useful commands and references
- A.10. Performance tuning on clients (updated May 2011)
- A.11. Example scripts and configuration files
- Appendix B: Medium to Large Configuration Upgrade
- Appendix C: Benchmarks and Test Tools
Dell HPC NFS Storage Solution - High Availability Configurations
Page 11
can first determine that the “passive” server is not providing the service. This is done by rebooting
or “fencing” the “passive” server.
Since fencing is a critical component for the operation of the HA cluster, the NSS-HA solution
includes two fence devices - the iDRAC and managed power distribution units (PDUs) – as previously
described in the section on NSS-HA Hardware. When the “active” server is trying to fence the
“passive”, fencing is first attempted by logging into the “passive” server’s iDRAC and rebooting the
“passive” server. If that fails, the “active” server attempts to log into the APC PDUs and power
cycle the power ports of the “passive” server. The “active” server tries these two fence methods in
a loop till fencing is successful.
The active-passive HA philosophy is that it is better to have no server providing the HA service than
to risk data corruption by having two active servers trying to access the same data volume.
Therefore it is possible to have a situation when neither server is providing the cluster service. In
this situation the system administrator will need to intervene and bring the cluster back to a
healthy state where the clients can access the data.
3.4. Potential Failures and Fault Tolerance Mechanisms
The NSS-HA includes hardware and software components to build in HA functionality. The goal is to
be resilient to several types of failures and transparently migrate the cluster service from one
server to the other. This section discusses the NSS-HA response to potential failures. Detailed
instructions on how to configure NSS-HA to tolerate these failures are provided in Appendix A: NSS-
HA .
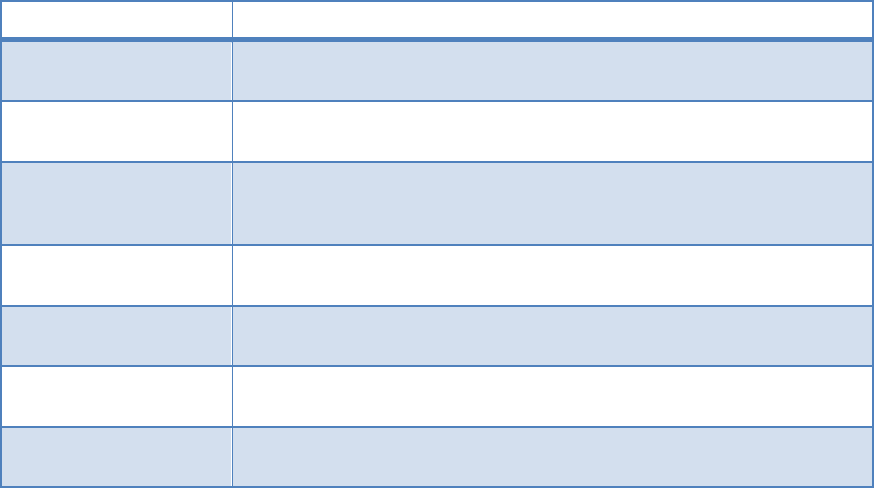
Assuming that the cluster service is running on the active server, Table 1
- NSS-HA Mechanisms to
Handle Failure
lists types of failure and the behavior of the NSS-HA cluster when the failure occurs.
Table 1 - NSS-HA Mechanisms to Handle Failure
FAILURE TYPE MECHANISM TO HANDLE FAILURE
Single local disk
failure on a server
Operating system installed on a two-disk RAID 1 device with one hot
spare. Single disk failure is unlikely to bring down server.
Single server failure Monitored by the cluster service. Service fails over to passive
server.
Power supply or
power bus failure
Dual power supplies in each server. Each power supply connected to
a separate power bus. Server will continue functioning with a single
power supply.
Fence device failure iDRAC used as primary fence device. Switched PDUs used as
secondary fence devices.
SAS cable/port failure Dual port SAS card with two SAS cables to storage. A single SAS
port/cable failure will not impact data availability.
Dual SAS cable/port
failure
Monitored by the cluster service. If all data paths to the storage are
lost, service fails over to the passive server.
InfiniBand /10GbE link
failure
Monitored by the cluster service. Service fails over to passive
server.