
Reference Guide










Performance evaluation and analysis
15 Reference Architecture of Dell EMC Ready Solution for HPC Life Sciences | Document 309
3 Performance evaluation and analysis
3.1 Variant calling analysis performance
A typical variant calling pipeline consists of three major steps:
1) aligning sequence reads to a reference genome sequence;
2) identifying regions containing SNPs/InDels; and
3) performing preliminary downstream analysis.
In the tested pipeline, BWA 0.7.2-r1039 is used for the alignment step, and Genome Analysis Tool Kit (GATK)
is selected for the variant calling step. These are considered standard tools for aligning and variant calling in
whole genome or exome sequencing data analysis. The version of GATK for the tests is 3.6, and the actual
workflow tested was obtained from the workshop, ‘GATK Best Practices and Beyond’. In this workshop, a new
workflow with three phases was introduced:
- Best Practices Phase 1: Pre-processing
- Best Practices Phase 2A: Calling germline variants
- Best Practices Phase 2B: Calling somatic variants
- Best Practices Phase 3: Preliminary analysis
Here we tested phase 1, phase 2A and phase 3 for a germline variant calling pipeline. The details of
commands used in the benchmark are in APPENDIX A. GRCh37 (Genome Reference Consortium Human
build 37) was used as a reference genome sequence, and 50x whole human genome sequencing data from
the Illumina platinum genomes project, named ERR194161_1.fastq.gz and ERR194161_2.fastq.gz were used
for a baseline test (15).
It is ideal to use non-identical sequence data for each run. However, it is extremely difficult to collect non-
identical sequence data having more than 50x depth of coverage from the public domain. Hence, we used a
single sequence data set for multiple simultaneous runs. A clear drawback of this practice is that the running
time of Phase 2, Step 2 might not reflect the true running time as researchers tend to analyze multiple
samples together. Also, this step is known to be less scalable. The running time of this step increases as the
number of samples increases. A subtle pitfall is a storage cache effect. Since all the simultaneous runs will
read/write roughly at the same time, the run time would be slightly longer in real cases. Despite these built-in
inaccuracies, this variant analysis performance test can provide valuable insights when estimating the level of
resources required for an identical or similar analysis pipeline with a defined workload.
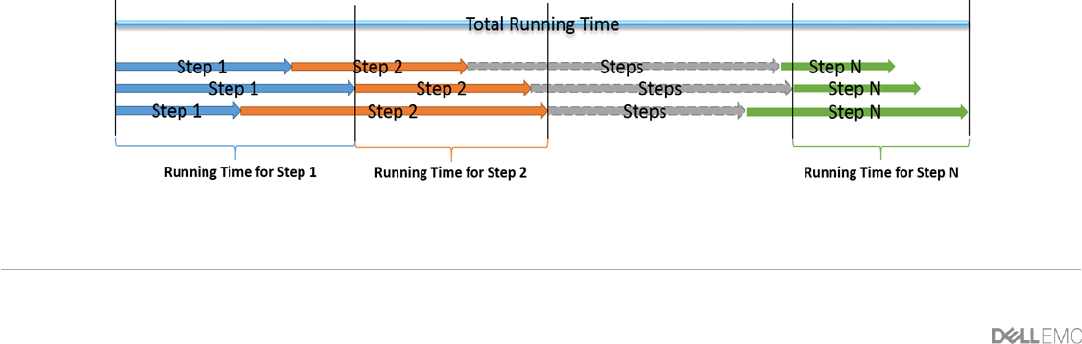
Total run time is the elapsed wall time from the earliest start of Phase 1, Step 1 to the latest completion of
Phase 3, Step 2. Time measurement for each step is from the latest completion time of the previous step to
the latest completion time of the current step as illustrated in Figure 6.
Figure 6 Running time measurement method